Characteristic polynomial
In linear algebra, one associates a polynomial to every square matrix: its characteristic polynomial. This polynomial encodes several important properties of the matrix, most notably its eigenvalues, its determinant and its trace.
The characteristic polynomial of a graph is the characteristic polynomial of its adjacency matrix. It is a graph invariant, though it is not complete: the smallest pair of non-isomorphic graphs with the same characteristic polynomial have five nodes.[1]
Contents |
Motivation
Given a square matrix A, we want to find a polynomial whose roots are precisely the eigenvalues of A. For a diagonal matrix A, the characteristic polynomial is easy to define: if the diagonal entries are a1, a2, a3, etc. then the characteristic polynomial will be:
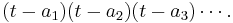
This works because the diagonal entries are also the eigenvalues of this matrix.
For a general matrix A, one can proceed as follows. A scalar 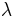 is an eigenvalue of A if and only if there is an eigenvector
is an eigenvalue of A if and only if there is an eigenvector 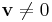 such that
such that
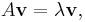
or
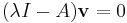
(where I is the identity matrix). Since v is non-zero, this means that the matrix I − A is singular, which in turn means that its determinant is 0 (non-invertible). Thus the roots of the function det( I − A) are the eigenvalues of A, and it is clear that this determinant is a polynomial in .
Formal definition
We start with a field K (such as the real or complex numbers) and an n×n matrix A over K. The characteristic polynomial of A, denoted by pA(t), is the polynomial defined by
- pA(t) = det(t I − A)
where I denotes the n-by-n identity matrix and the determinant is being taken in K[t], the ring of polynomials in t over K. (Some authors define the characteristic polynomial to be det(A − t I). That polynomial differs from the one defined here by a sign (−1)n, so it makes no difference for properties like having as roots the eigenvalues of A; however the current definition always gives a monic polynomial, whereas the alternative definition always has constant term det(A).)
Example
Suppose we want to compute the characteristic polynomial of the matrix
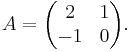
We have to compute the determinant of
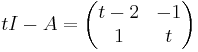
and the corresponding determinant is
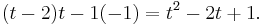
This is the characteristic polynomial of A.
Properties
The polynomial pA(t) is monic (its leading coefficient is 1) and its degree is n. The most important fact about the characteristic polynomial was already mentioned in the motivational paragraph: the eigenvalues of A are precisely the roots of pA(t) (this also holds for the minimal polynomial of A, but its degree may be less than n). The coefficients of the characteristic polynomial are all polynomial expressions in the entries of the matrix. In particular its constant coefficient is equal to (−1)ndet(A), and the coefficient of t n − 1 is equal to −tr(A), the matrix trace of A. For a 2×2 matrix A, the characteristic polynomial is therefore given by
- t 2 − tr(A)t + det(A).
The Cayley–Hamilton theorem states that replacing t by A in the characteristic polynomial (interpreting the resulting powers as matrix powers, and the constant term c as c times the identity matrix) yields the zero matrix. Informally speaking, every matrix satisfies its own characteristic equation. This statement is equivalent to saying that the minimal polynomial of A divides the characteristic polynomial of A.
Two similar matrices have the same characteristic polynomial. The converse however is not true in general: two matrices with the same characteristic polynomial need not be similar.
The matrix A and its transpose have the same characteristic polynomial. A is similar to a triangular matrix if and only if its characteristic polynomial can be completely factored into linear factors over K (the same is true with the minimal polynomial instead of the characteristic polynomial). In this case A is similar to a matrix in Jordan normal form.
Characteristic polynomial of a product of two matrices
If A and B are two square n×n matrices then characteristic polynomials of AB and BA coincide:
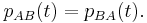
More generally, if A is m×n-matrix and B is n×m matrices such that m<n, then AB is m×m and BA is n×n matrix. One has
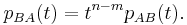
To prove the first result, recognize that the equation to be proved, as a polynomial in t and in the entries of A and B is a universal polynomial identity. It therefore suffices to check it on an open set of parameter values in the complex numbers. The tuples (A,B,t) where A is an invertible complex n by n matrix, B is any complex n by n matrix, and t is any complex number from an open set in complex space of dimension 2n2 + 1. When A is non-singular our result follows from the fact that AB and BA are similar:
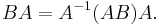
Types
Characteristic equation
In linear algebra, the characteristic equation (or secular equation) of a square matrix A is the equation in one variable λ
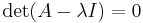
where det is the determinant and I is the identity matrix. The solutions of the characteristic equation are precisely the eigenvalues of the matrix A. The polynomial which results from evaluating the determinant is the characteristic polynomial of the matrix. The term "characteristic equation" is due to Wilhelm Killing.
For example, the matrix
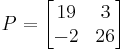
has characteristic equation
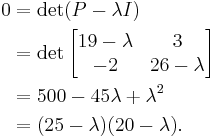
The eigenvalues of this matrix are therefore 20 and 25.
Some shortcuts exist for low dimension matrices. For a 2×2 matrix A, the characteristic polynomial can be found from its determinant and trace, tr(A), to be
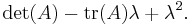
For a 3×3 matrix, we define c2 as the sum of the principal minors of the matrix, and find the characteristic polynomial to be
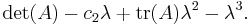
The Cayley–Hamilton theorem states that every square matrix satisfies its own characteristic equation.
Secular function
The term secular function has been used for what mathematicians now call a characteristic function of a linear operator (in some literature the term secular function is still used). The term comes from the fact that these functions were used to calculate secular perturbations (on a time scale of a century, i.e. slow compared to annual motion) of planetary orbits, according to Lagrange's theory of oscillations.
In linear algebra, zeros of a secular function are the eigenvalues of a matrix. Characteristic polynomials also have eigenvalues as roots.
The characteristic polynomial is defined by the determinant of the matrix with a shift. It has zeros only, without any pole. Commonly, the secular function implies the characteristic polynomial. But, in the strict sense, the secular function has poles as well. Interestingly, the poles are located in the eigenvalues of its sub-matrices. Thus, if the information of the sub-matrices is available, the eigenvalues of the matrix can be described using that kind of information. Furthermore, by partitioning the matrix like matrix tearing or gruing, we can iterate the eigenvalues in a recursive way. According to the methods of partitioning, the variant forms of the secular functions can be built up. However, they are all of the form of a series of the simple rational functions, which have poles at the eigenvalues of the partitioned matrices. For example, we can find a form of secular function in the divide-and-conquer eigenvalue algorithm.
Recently, the secular function has been utilized in signal processing. The estimation problem with uncertainty involves a sort of eigenvalue problem, such as a bounded data uncertainty, total least squares, data least squares, partial least squares, errors-in-variables model, etc. Many cases have been solved using their own secular equations. Some are still trying to find the unique secular equation that can resolve a given uncertainty estimation problem.
As for a numerical aspect, it is known that Newton's method is delicate when finding the roots of the secular equation. The higher-order interpolations are recommended. Among them, a simple rational approximation is a good choice considering the balance between the stability and the computational complexity. It is because the secular equation itself consists of a series of simple rational functions. However, using only interpolation cannot guarantee the stability. Thus fine search algorithms such as bisection steps are still required for accuracy.
Secular equation
Secular equation has several meanings.
In mathematics and numerical analysis it means characteristic equation.
In astronomy it is the algebraic or numerical expression of the magnitude of the inequalities in a planet's motion that remain after the inequalities of a short period have been allowed for.[2]
In molecular orbital calculations relating to the energy of the electron and its wave function it is also used instead of the characteristic equation.
See also
References
- ^ "Characteristic Polynomial of a Graph - Wolfram MathWorld". http://mathworld.wolfram.com/CharacteristicPolynomial.html. Retrieved August 26, 2011.
- ^ "secular equation". http://dict.die.net/secular%20equation/. Retrieved January 21, 2010.